티스토리가 싫어요.
티스토리의 불편함을 감수하고 꽤 오랜 시간을 사용했다. 이전에는 클라우드형 뿐만아니라 설치형 블로그까지 모두 설렵했다. 설렵한 항목들 중 그나마 불편함이 적은 티스토리에 정착했었다. 불편함은 이제 너무나 친숙해서 더 이상 불편함을 인지 못하고 있었다.
귀찮음이 불편함을 이긴 순간이었다.
그런데 갑작스레 이전을 생각한 결정적 계기는 에디터 였다. 티스토리 에디터를 통해 본문을 수정하면, 의도치 않게 강제로 p 태그 등에 style attribute 가 추가되었다. 이로하여 내 블로그 글들은 전부 폰트 및 사이드가 뒤죽박죽이 되어, 도저히 글을 읽을 엄두가 안나게되었다. 티스토리 스킨에서 별도로 javascript 로 위 문제에 대한 정규식을 구해 치환해보았지만, 이 또한 클라이언트 사이드에서 불 필요한 coast 였다. 이렇게 클라이언트 사이드에서 강제한다고 한 들, 이미 망가져린 문서 format 을 보니 더 이상의 인내는 없었다.
이사 짐을 꾸려요.
작성한 글들을 markdown 으로 정적으로 정제하고 싶었고, 그 결과 Jekyll, Hexo 라는 선택지가 주어졌고 후보군 둘다 고만고만하여 일전에 사용해본 Jekyll 을 사용하기로 했다. jekyll 에 대해 간략하게 소개하자면 웹사이트 생성 도구다. Markdown, Liquid, YAML, HTML/CSS 등을 편집하고 jekyll 서버를 동작하면 정적 웹 페이지를 생성해준다.

Chicago Modifications by Papa Lima Whiskey
{kind=link}
블로그나 프로젝트 웹페이지로 안성맞춤이다
github 에서는 너무나 고맙게도 github page 라는 서비스를 제공하기에 무료 호스팅을 사용할 수 있다. (Thanks github) git repository에 gh-pages 브렌치를 만들고 index.html 파일생성하면 프로젝트 사이트를 만들 수 있으니 정말 편하다. 프로젝트 페이지 말고 github account 를 통해 생성할 수 있는데, 이는 {github account}.github.io 도메인을 부여받는다.
나의 github 계정은 webhacking 이니 webhacking.github.io 가 되겠다. 항상 계정명을 보면 네이밍의 중요성을 느낀다.. 중학교 때 사용한 닉네임인데 어른이 되어서 후회할 줄 이야.. markdown이라는 선택은 훗 날로 하여금 Jekyll 이 아니더라도, 언제든 다른 플랫폼으로 이전할 수 있다는 이점도있다. 이와 동시에 단점도 동시하는데, Jekyll 은 static html generator 격인데 현재 markdown 문서 500건 기준으로 생성하는데 소요되는 시간이 6 seconds 다. 이는 절대 간과할 수 없는 시간이며.. 결국엔 저 소요 시간은 문서의 비례하기에 문서가 증가하면 소요시간이 더 증가하게 되 있어.. 먼 훈날 10초 이상을 기다려야 할 수 도 있다.
이 부분에 대해 검색해보면 여러 optimize 방안이 나오니 크게 문제될 것 은 없다.
16년 8월 부터, github page 에서 Jekyll 3.2를 적용하고있다. 해당 버전에서 성능 이슈 또한 많이 개선되었으니 앞으로도 많은 발전이 있을 것이라 생각한다. 위 성능부분을 제외하고 이전을 생각하면서 대비해야할 항목이라고 생각한 건 기존 URI 와의 Link 였다. 티스토리는 기본적으로 문서의 sequence number 로 URI에 표기하는 반면 Jekyll 의 경우 자유럽게 표현 할 수 있지만 통상 날짜-제목 으로 표기하기에 고민이 되었다. 그렇다고 본인이 sequence number 를 매기면서 까지 문서를 작성하는 건 실상 너무 비효율적이라 후보군에도 제외되었다. 많은 시간 여러 검색 엔진들의 봇이 나의 문서와 관련된 정보를 parsing 한 상태이고 여기서 이전 링크와 관련된 요소들을 포기하고 후자의 format 으로 URI을 사용하게 되면 검색 유입자들과 더불어 검색 엔진들에도 신용도를 잃을 것 이다.
이 신용도는 SEO 에 영향을 미치는데, 나의 블로그는 신용도를 잃어서 검색 유입도 줄어들 것 이다.
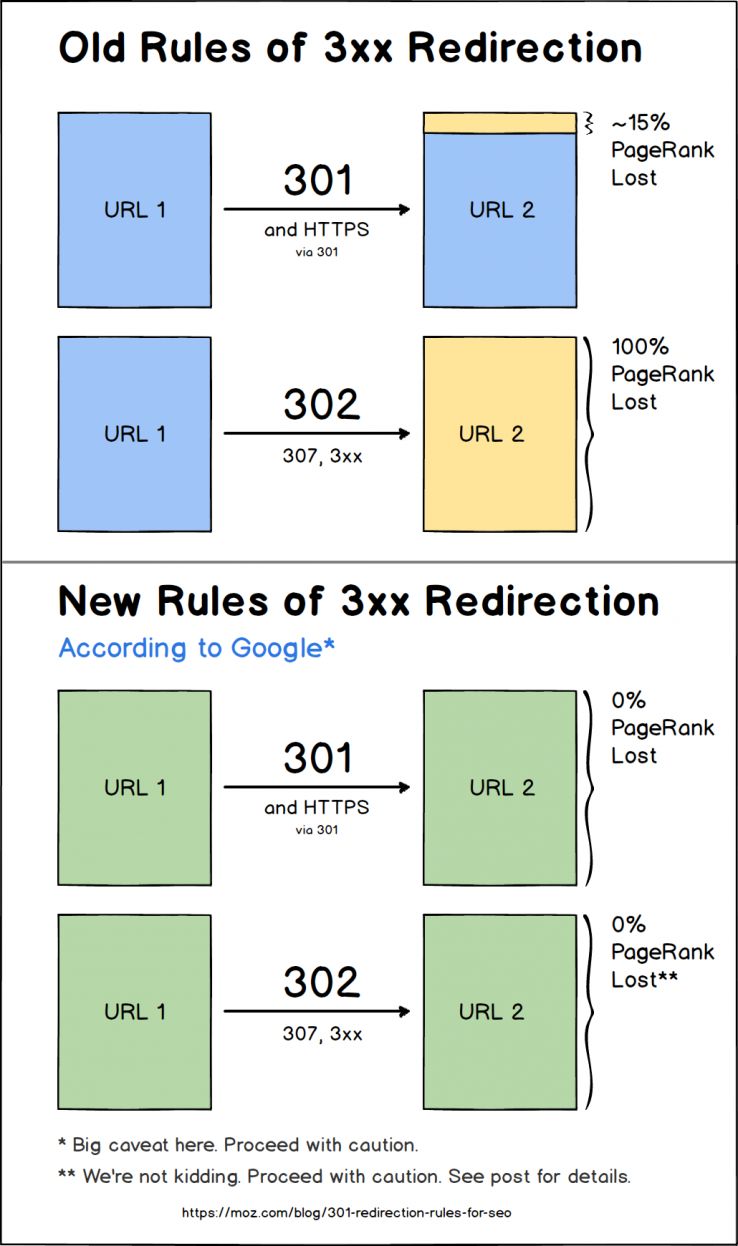
그렇다면 기존 URI 로 접근 시, 새로운 URI 로 Redirect 하자. 구글 엔진의 경우 일전까지 30X 상태코드에대해서 PageRank가 약 15% 손실되었다고한다. 하지만 지금은 아니다.
30x redirects don't lose PageRank anymore.
— Gary "鯨理" Illyes (@methode) July 26, 2016
아래는 Google에서 발표한 기존과 변경된 개념을 설명하는 다이어그램입니다
손실을 방지할 수 있는 방법도 강구했으니, 문서 이전을 시작해보자. 먼저 이전에 작성한 문서들을 전부 옮겨야 하는데, 2016년도 부터 티스토리는 백업 및 Blog API 기능을 종료하였다. 따라서 별도의 코드를 작성하기로 했다. 내가 작성한 Python 코드는 Github 에 공유했다. 아래 main.py 에서 1부터 최근 마지막 작성한 sequence number 를 구해, 순차적으로 parsing 하여, 본문을 markdown 문법으로 치환 후 메타데이터 및 이미지 파일과 함께 저장을 한다.
import re, html2text
from Tistory.Post import Post
post = Post(blog='http://blog.hax0r.info', image_dir='assets/images/posts/')
for i in range(1, post.latest()):
content = post.read(i)
if content:
print('수행 :' + str(i))
h = html2text.HTML2Text()
markdown = h.handle(content[0])
replaced = """
---
layout: post
title: "%s"
description: ""
date: %s
tags: %s
comments: true
share: true
---
""" % (content[1]['title'], content[1]['published_date'], content[1]['tags'])
file = open('Storage/Posts/' + str(content[1]['published_date']) + '-' + str(i) + '.md', 'w')
file.write(re.sub(r'(^[ \t]+|[ \t]+(?=:))', '', replaced, flags=re.M) + '\n' + markdown)
file.close()
아래는 Post.py 의 내용이다. 전반적으로 specifically 나의 이전 블로그에 초점을 두고 있어, 만약 사용한다면 조금 수정이 필요할 것 이다.
일전에 언급했 듯, 본인은 귀찮음으로 불편함을 이기는 사람이다.
따라서 급히 작성한 코드라 그리 예쁘지 않다는 점을 이해해주길 바란다.
import os
import re
import requests
from datetime import datetime
from PIL import Image
from Tistory.Base import Base
from bs4 import BeautifulSoup
class Post(Base):
def __init__(self, image_dir, blog):
super().__init__()
self.image_dir = "Storage/Images/"
self.blog = blog
if image_dir :
self.image_dir = image_dir
def make_relate_dir(self, page_number):
if not os.path.exists(self.image_dir):
os.makedirs(self.image_dir)
if not os.path.exists(self.image_dir + str(page_number)):
os.makedirs(self.image_dir + str(page_number))
@staticmethod
def clean(html):
cleanr = re.compile('<.*?>')
return re.sub(cleanr, '', html)
def latest(self):
response = requests.get(self.blog + '/', headers=self.header)
soup = BeautifulSoup(response.content, 'html.parser')
body = soup.select('body')
posts_numbers = []
for link in body[0].find_all('a'):
if link.has_attr('href'):
if not link['href'].replace('/', '').isdigit():
continue
posts_numbers.append(int(link['href'].replace('/', '')))
return sorted(posts_numbers, reverse=True)[0]
def read(self, page_number):
response = requests.get(self.blog + '/' + str(page_number), headers=self.header)
soup = BeautifulSoup(response.content, 'html.parser')
body = soup.select('.tt_article_useless_p_margin')
if not body:
return False
for image in body[0].find_all('img'):
self.make_relate_dir(page_number)
path, file_name = os.path.split(image['src'])
im = Image.open(requests.get(image['src'], stream=True).raw)
im.save(os.path.join(self.image_dir + str(page_number), file_name + "." + im.format), quality=85)
image['src'] = self.image_dir + str(page_number) + "/" + file_name + "." + im.format
tags = []
title = soup.select('h3.tit_post')[0].text
published_date = datetime.strptime(re.search(r'\d{4}.\d{2}.\d{2}', str(soup.select('span.info_post')[0])).group(), '%Y.%m.%d').date()
for tag in soup.select('#mArticle dl.list_tag a'):
tags.append(tag.text)
for code in soup.find_all("code"):
code.replace_with(self.clean(str(code.findChildren()[0])))
content = str(body[0]).split('<div class="container_postbtn">')[0]
return content, {
'title' : title,
'published_date' : published_date,
'tags' : tags
}
이사 끝
귀찮음을 이기고, 마주한 블로그는 아주 마음에들었다. 오랜글들을 다시금 볼 수 있는 기회였고, 덕분에 창피함이 무엇인지 다시금 상기되었다. 현재 테마에서 카테고리, 검색, 포스트 본문 이외 여러부분을 따로 많은 부분을 신경써야한다는 애로사항이 존재했지만 이 또한 높은 자유도라 생각하고 재밌게 그려냈다.
본질인 글을 전달하고 싶다.
이전 티스토리 블로그는 폐쇄할 계획이며, 폐쇄가 되면 모든 데이터는 삭제된다고한다. 그래서 혹시 몰라서 아래와 같이 치환하지 않은 본문 문서를 따로 postfix로 backup을 붙여 저장하기로 했다.
더 이상 블로그를 이전하고 싶지 않다.
왠만하면 테마를 변경하는 일에 내 시간을 쏟고 싶지도 않다.

영준 (=hax0r)
https://www.hax0r.info
I am a passionate back-end developer always in hunger of learning new things and sharing what i have learned. who loves challenges, newest technologies and programming at all.