Overview
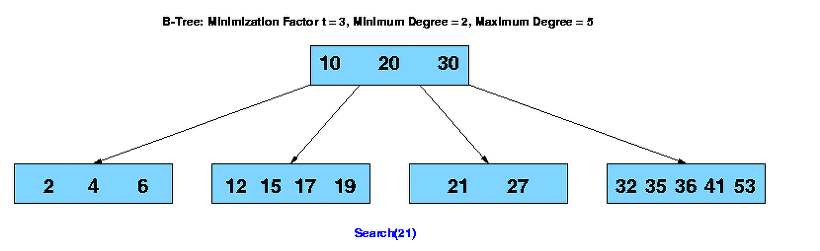
RDBMS에서 대부분의 경우 일반적으로 사용되는 자료 구조는 B-Tree 입니다.
Primary Key 순으로 정렬하여 관리하고 Secondrary Key는 인덱스키 + PK를 조합하여 정렬하고있습니다.
데이터의 사이즈가 커져도 특정 데이터 접근에 소요되는 비용이 크게 증가되지 않기 때문입니다.
또 노드의 삽입, 삭제 후 에도 균형 트리 유지로 균등한 응답속도 보장하고 효율적인 알고리즘 제공합니다.
PK로 접근 시 데이터 접근에 소요되는 비용은 O(logN)이고,
두번째 트리에 접근하는 Secondrary Key에 소요되는 비용은 2 * O(logN)입니다.
단점도 존재하는데, 삽입과 삭제시 트리의 균형을 유지하기 위해 복잡한 연산(재분배,합병)이 필요
(½일 때 분열이 일어남, 2/3일 때 분열이 되는 B*TREE 활용)합니다.
또한 Mutex Lock이 과도하게 생성되면 적은 데이터 셋에도 자원 사용 효율이 감소하게 됩니다.
_자주 사용되는 데이터 탐색에도 불구하고 매번 트리의 경로를 쫓아_가야 한다는 애로사항이 있습니다.
이와 같은 애로 사항 때문에 퍼포먼스를 최대로 발휘하지 못 하는 경우가 많습니다.
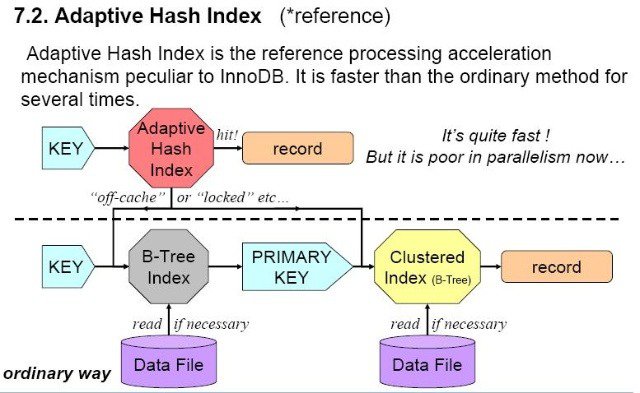
이에 대한 해결책으로InnoDB에는 Adaptive Hash Index 를 지원합니다.
InnoDB Adaptive Hash Index는 B-Tree의 한계를 보완할 수 있는 좋은 기능입니다.
Adaptive Hash Index ?
The adaptive hash index (AHI) lets InnoDB perform more like an in-memory database on systems with appropriate combinations of workload and ample memory for the buffer pool, without sacrificing any transactional features or reliability
Adaptive Hash Index 는 _자주 사용되는 칼럼_을 해시로 정의합니다.
B-Tree를 이용하지 않고 다이렉트로 데이터에 접근할 수 있는 기능인 것 입니다.
모든 값을 해시로 생성하는 것이 아닌, _자주 사용되는 데이터 값만 내부 알고리즘을 통해 해시 값을 생성_합니다.
장점을 얘기해봤으니 단점도 알아봅시다.
Adaptive Hash Index는 사용되는 데이터를 내부 알고리즘이 판단하여 해시 키를 생성하기 때문에 제어가 어렵습니다.
오랫동안 사용되지않은 테이블이라도 기존 해시 자료 구조가 남아있기 때문에 테이블 drop 시 영향을 줄 수 있습니다.
설정을 enable 하고자 한다면 아래 명령어를 참고하시면 됩니다.
(innodb_adaptive_hash_index 파라미터는 InnoDB Plugin 1.0.3 부터 동적으로 Global 변수를 변경 가능합니다.)
set global innodb_adaptive_hash_index = 1;
반대로 설정을 disable 하고자 한다면 아래 명령어를 참고하면 됩니다.
set global innodb_adaptive_hash_index = 0;
설정 값을 보고자 한다면 아래의 명령어를 참고하면 됩니다.
show variables like '%adaptive%';# 아래 정보는 저의 환경에서 실행한 결과 값 입니다.'innodb_adaptive_flushing', 'ON''innodb_adaptive_flushing_lwm', '10''innodb_adaptive_hash_index', 'ON''innodb_adaptive_max_sleep_delay', '150000'
통계 정보는 아래 명령어를 통해 참고 할 수 있습니다.
show global status like 'Innodb_adaptive_hash%';
Reference

영준 (=hax0r)
https://www.hax0r.info
I am a passionate back-end developer always in hunger of learning new things and sharing what i have learned. who loves challenges, newest technologies and programming at all.