해외 메이져라 칭할 수 있는 큰 규모의 서비스들의 데이터베이스 스택을 보니 카산드라가 자주 등장한다.
페이스북,트위터등 데이터 처리가 높은 SNS 서비스에서 많이 사용되고있다.
팀원과 프로젝트 진행하면서 데이터베이스를 무엇을 사용할까 얘기하던 중
몽고,다이나모,MySql,Redis 이외 기타 등등, 그러고보니 요즘 데이터베이스 제품 군도 참 다양해서 개발자들이 선택하는 재미가 있는 것 같다.
다이나모랑 Redis 랑 MySql은 회사에서도 계속 사용중이니 별로 관심 밖이었고 몽고는 예전에 사용해본 결과 좋은 인상이있었는데 이번에 항상 보기만 했던 카산드라를
사용해보고자했다. 사용하기 앞서 카산드라의 짧은 개념 및 설명을 하려고한다.
아직 카산드라를 사용해보지않아서 카산드라와 몽고 db 의 차이점을 논할수없지만, 어떤 분 께서 친절하게 두 제품군을 비교한 내용이있어
참고하여 적어본다. 몽고db와 카산드라를 퍼포먼스 면에서 비교하자면 몽고db쪽이 앞선다고 말할수있다.
몽고는 쓰기할때 메모리에 먼저 Write 후에 1분 단위로 Flushing하는 Write back 방식을 사용한다.
메모리에만 쓰면 되니깐 쓰기가 매우 빠르다. 반대로 읽을때는 파일의 인덱스를 메모리에 로딩해 놓고 찾는다.(memory mapped file) memory mapped file 덕북에 성능에서 우위일수있겠지만 제약이 많고 Configuration 구조상 메모리 사용량이 많으며 확장에도 제약이있다.
카산드라는 Write back이나 memory mapped file을 사용하지 않기 때문에 몽고디비에 비해서 성능이 낮을 수 밖에 없다. 더군다나 쓰기나 읽기시 1개 이상의 Node에서 값을 읽거나 쓰기 때문에Consistency가 mongoDB에 비해서 나르며 당연히 확장성도 높다.
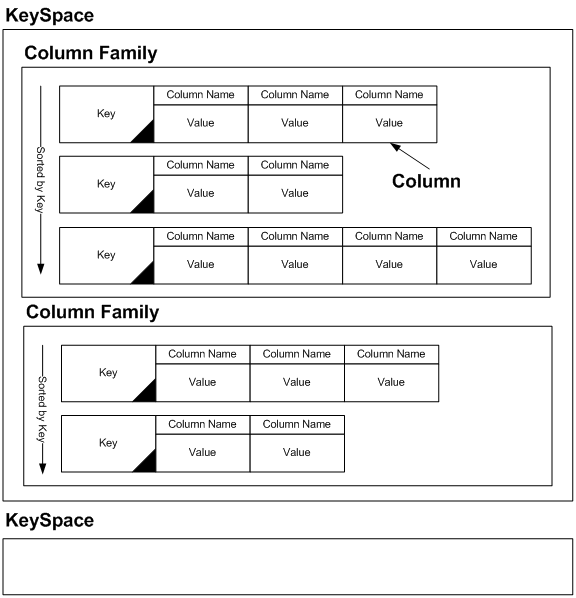
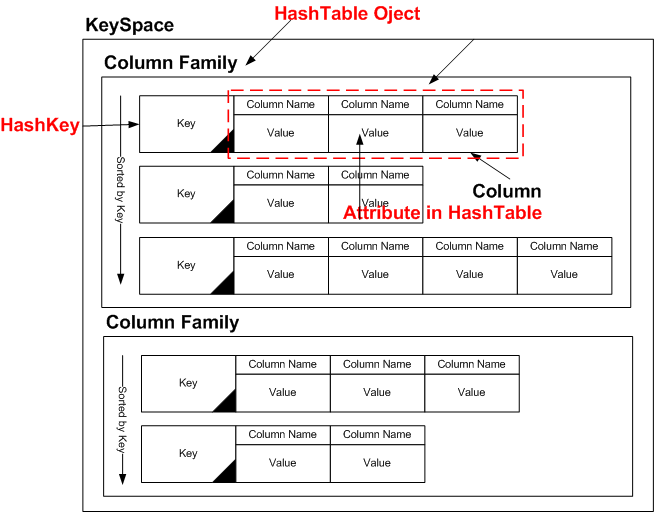
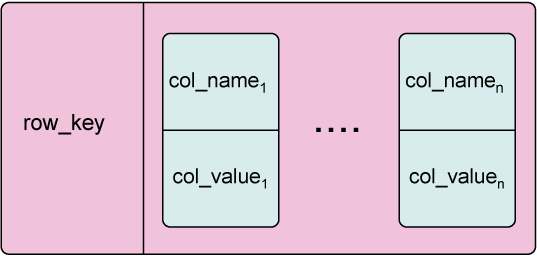
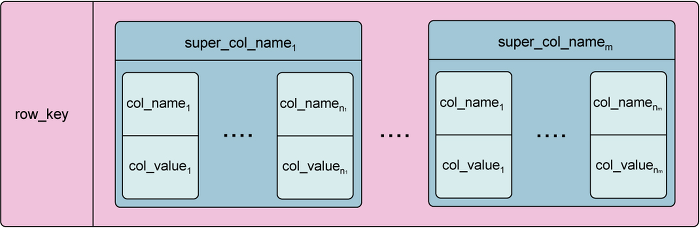
카산드라는 구글의 BigTable 컬럼 기반의 데이터 모델과 페이스북에서 만든 Dynamo의 분산 모델을 기반으로 제작되어 Facebook에 의해 2008년 아파치 오픈소스로 공개된 분산 데이터 베이스입니다. 기존 관계형 데이터베이스에 벗어나 SQL을 사용하지않는 Nosql 제품중 하나입니다.
대용량의 데이터 트렌젝션에 대해서 고성능 처리가 가능한 시스템(“High-Scale”)입니다.
노드를 추가함으로써 성능을 낮추지 않고 횡적으로 용량을 확장할 수 있다.
데이터간의 복잡한 관계정의(Foreign Key)등이 필요없고, 대용량과 고성능 트렌젝션을 요구하는 서비스에서 많이 사용되고있다.
DataStax Cassandra Tutorials - Apache Cassandra Overview
특징
- Distribute (분산성)
카산드라는 데이터 분산 이 뛰어납니다.
카산드라는 컨시스턴트 해싱(consistent hashing)을 사용하여 데이터를 분산합니다.
컨시스턴스 해싱이란?
컨시스턴트 해싱은 메타정보를 조회하지 않아도 클러스터에서 키가 저장된 노드를 바로 찾아갈 수 있는 방법입니다. 키의 해시 값을 구해서 키를 찾고, 이 해시 값만으로 노드를 찾아갈수있습니다. 일련의 해시가 값을 가상의 링에 순서대로 나열했다고 가정하고 각 노드는 링에서 각자 맡은 범위만 처리하는 방법입니다. 만약 노드를 추가하면 많은 데이터를 가진 노드가 맡고 있던 범위를 분활하여 새 노드에 할당합니다. 노드를 삭제할때는 링에서 삭제된 노드가 맡고 있던 범위를 인접노드가 맡습니다.
따라서 서비스 중에도 노드의 추가/삭제로 인해 영향을 받는 노드 수를 최소화 할 수 있습니다.
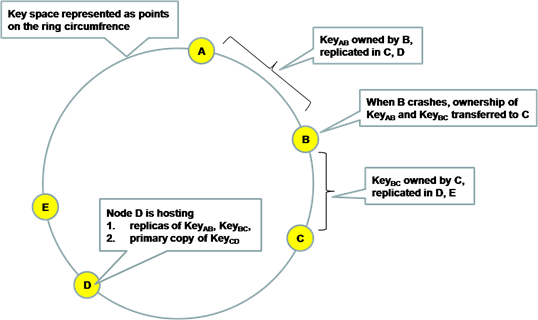
조금 더 사용해보고 해당 포스트를 다듬겠습니다.
참고

영준 (=hax0r)
https://www.hax0r.info
I am a passionate back-end developer always in hunger of learning new things and sharing what i have learned. who loves challenges, newest technologies and programming at all.